This is more a Natural History Collections “in general” question than a Specify-specific one, but I was wondering if there is an accepted protocol for how to deal with Agent name changes. I suspect that for some Agents, like every department with Game in the title that switched to Wildlife you can have the modern name appear in all instances, and simply keep a list of AKAs in the Agent comments, but what about name changes due to marriages? Should a specimen collected by that Agent always show the name the last “correct” name? Would there even be a way to do otherwise, display a different name for a different year range?
Hi @VHough,
That’s a great question, and this is a common challenge. I will leave the curatorial perspective to others who have insight to share, but the Specify platform has a preferred way of handling it that captures historical context.
Specify’s principle on agents is that each unique person, group, or organization should have only one Agent record. With this approach, you avoid the ambiguity and it makes it easy to search for all specimens collected by a person, regardless of what point in their life it took place.
The best practice in Specify is to use the current, most up-to-date name for the primary Agent record and to store all previous names as Agent Variants.
This is a more structured approach than using the remarks field because it allows you to categorize the type of name change.
For your specific scenarios:
- For a department that changed its name from “Department of Game” to “Department of Wildlife,” the primary Agent record’s name would be “Department of Wildlife.” You would then create an Agent Variant with the name “Department of Game” and select (or create) a
Typelike “Former Name.” - The same logic applies for a personal name change. The primary record for the person should use their current legal name. You would then add their maiden name as an Agent Variant, with a
Typeof “Maiden Name”, “Variant Name”, "Birth Name, or “AKA.”
In short, we recommend showing and using the last “correct” name while capturing any variants as attributes of the agent on the form.
In addition to capturing variants, we encourage you to add ORCID and/or Wikidata IDs to agents using the Agent Identifiers system. This will allow you to uniquely identify them, regardless of any future name or status changes:
@VHough this is an age old question, and one that has no perfect answer I’m afraid.
For people, I use the agent’s current legal name as the agent name, and all other forms become Agent Variants. This is somewhat problematic in that reprinting a label for an old lot may in some cases produce a different name than the agent had when the lot was collected. Also, legal transaction records such as loans, accessions, or permit records become inconsistent with what ‘actually’ happened. I believe DarwinCore expects data providers not to do this and to keep verbatim names instead and use separate IDs (dwc:recordedbyID) to link to agent records.
However, that isn’t easy to do in Specify, and I view these changes as pretty easy to understand if one examines the Agent record and sees the Agent Variant record for the prior name. In the few prominent cases I’ve dealt with so far in my collection (someone being maried and divorced a few times) I believe I added the full married names with MarriedName (née BirthName) as a variant, even if it didn’t occur on a label.
RE institutions, I’m still deciding exactly how I want to deal with these, but right now I give each name its own agent record, because the legal institutional name is more important for provenance and variation is generally less easily understood than personal name changes. Sometimes a name change can indicate a change in actual administrative structure of an organization, like the splitting off of a division or something. Our own institution has a very convoluted administrative history. There are 3 separate entities within our university that over the years have called called themselves The Ohio State University Museum of Zoology (or something close to it), for example, and though there’s a through-line connecting all of those to our current museum, those entities are not the exact same institution as we are now. I’d be interested to hear if you encounter examples like that!
As an example from an adjacent field: the Biodiversity Heritage Library typically gives unique records to journals when they change names, but they reciprocally link the new journal name to the old journal name to indicate the continuity.
On the Specify technical side of things, this question also brings up some problems I’ve noticed with the Agent Variant tables that I’ve spoken about with @SpecifyMembership before.
- Agent Variants are single fields, meaning the name part parsing and structure of the Agent record is lost when turning it into an Agent Variant.
- Agent Variants do not get considered upon upload (duplicate agent is created even if that agent string exists as the agent variant of an existing agent).
- When Agent Variants are automatically created using the record merge tool on records in the Agent table, the GUID for the Agent record that becomes an Agent Variant gets destroyed in the process, meaning agent GUIDs in Specify are not persistent identifiers (for example, if you accidentally upload one or more duplicate agents and then merge them with the existing agent with the same data, you can only keep one GUID, meaning existing external references to a merged agent record(s) by GUID would be unresolvable in the future because that original GUID(s) are no longer stored anywhere.)
- I believe this situation is partly what @dshorthouse was referring to in this post, and I think it’s a very good point that should probably be addressed in a future update (by making Agent Variants retain the GUID of the Agent they came from, at least).
With the way these two tables currently function, I’ve frequently thought that it would probably result in fewer duplicate agents and less work and cleaning on the part of curatorial staff to leave agent strings completely unparsed in Specify 7 databases, because parsing to name parts offers almost no benefit beyond being able to sort the name parts alphabetically in query results. As name strings can’t be abbreviated or matched programmatically (i.e. I can’t tell specify to print my name as N.F. shoobs on a label unless I manually make that the preferred form of my agent record and make my full name a variant, or add initials in a separate field), and a partially parsed or unparsed name string uploaded via the workbench always results in a duplicate agent record even when an Agent Variant record exists that is verbatim match to the uploaded string.
It’s a shame, because there’s a lot of power that could be leveraged with some trivial changes!emphasized text
That’s a very good point about institutions that I hadn’t thought of! It’s easier to know if something like that is happening if they have a good wikipedia page, but some institutions I’ve been unable to find a clear understanding of their history.
I will say that *pre-*Specify, parsing has been very useful for finding agent duplicates, but in theory that wouldn’t be useful any more once in the system, I get that. I don’t know enough about the technical side of things to say anything intelligent about implementation, besides “wouldn’t it be nice if all these name who we knew were the same person got to stay as they were but be linked to a common GUID.” At least if the person is alive and easy to contact I can ask them directly how they’d like to be represented. But you’re right, it seems like it wouldn’t be too hard to select “print abbreviation on label” since there is an abbreviation field already.
Thanks for your thorough response to my question!
Hi @nfshoobs,
Thank you for adding your insights! It is very helpful to have the real world examples and a breakdown of the pros and cons of different approaches.
Maintaining persistent identifiers is a valid concern. We have documented the GUID loss during Agent merging issue for our programmers to investigate and prioritize. It can be found here: https://github.com/specify/specify7/issues/7502.
As you mention, Agent Variants do not get considered when uploading data through the Workbench or when searching for an existing agent, as we have discussed previously. This would offer a new enhanced, functionality for matching data, affecting Workbench, query builder operations, and table searches. In order for our developers to investigate and prioritize this enhancement, they need to have use cases and requirements they can reference in order to gage the scope of the work involved. If you can send use cases and requirements as you understand them, I can start a document on requirements for this feature and prepare it for the programmers.
Please feel free to contact me at membership@specifysoftware.org to move forward on the requirements.
@SpecifyMembership Thanks for offering to get a proposal together for this feature. This issue is one of those things that is “simple, yet complex” in that I think there are many different ways that one could solve it, each of which may break some workflows in some collections. I added a comment to the github issue as well, but here I’ll outline what I think of as the main problem, and a way to solve it:
A basic problem endemic to the Specify model for agents (and probably all software that deals with lists of peoples names) is that the most common input is either a single complete (unparsed) name, or a delimited list of complete (unparsed) name parts, which may be separated and abbreviated in a bunch of different ways. Collections must spend considerable time parsing names to be in the format required.
One way to potentially speed this up might be the following:
- The field designated as the “agent list” (e.g., Collector, Identifier, Cataloger, etc.) is split on common delimiters, ignoring spaces:
,,;,&,and,|
- Each trimmed substring is searched against a list of all Agents and AgentVariants in the database, with permutations as listed below:
Agent.FullName(exact, case-insensitive)AgentVariant.Name(exact, case-insensitive)- Optional: abbreviated versions of names not currently present as agent variants (for example, initializing only the first initial, only the middle name, or both.
*Optional: other formats of all of the above, bothfirst middle last, andlastname, first middle
- If all substrings find exact matches, the system:
- Assigns those agents to the record in the order found
- Logs confirmation in upload report (e.g.,
Matched: Watters, G.T.; Stansbery, D.H.)
- If some substrings fail to match:
- The system highlights them for user disambiguation
- No new agent records are created unless explicitly approved
A threshold could be applied (for example, with fuzzy matches/levenstein distances, like in OpenRefine)
Of course, this entire feature should also be a setting in the workbench preferences for a user, like: “Use existing Agent and AgentVariant records to validate and populate agents for uploaded records? y/n” .
One could make the argument that this kind of cleaning is better done outside of the software, (for example, in OpenRefine, or pandas in Python). But the fact is that almost all input into the workbench is and will continue to be in the form of lists of unparsed agent names, many of which may already be represented in a given database. Case in point, the last big workbench upload I did, I spent at least an hour monkeying around with the parsing of the agent fields for a dataset that only included 3 or 4 agents, all of whom were already present in the database. But because their names were recorded inconsistently in the incoming dataset, there was no easy way to get specify to recognize them without creating duplicates, even though every single form of each name was present already as an agent variant.
99+% of people who generate and disseminate biodiversity data record their agent data as unparsed, at least partially special-character delimited lists of agents in a single field in a flat spreadsheet. As such, it probably makes sense to design Specify with this in mind to lighten the burden of parsing and normalizing these data for the user, and to enable the user to harness the wealth of data already present in their Specify database already in order to normalize and parse agent data.
@VHough Any ideas?
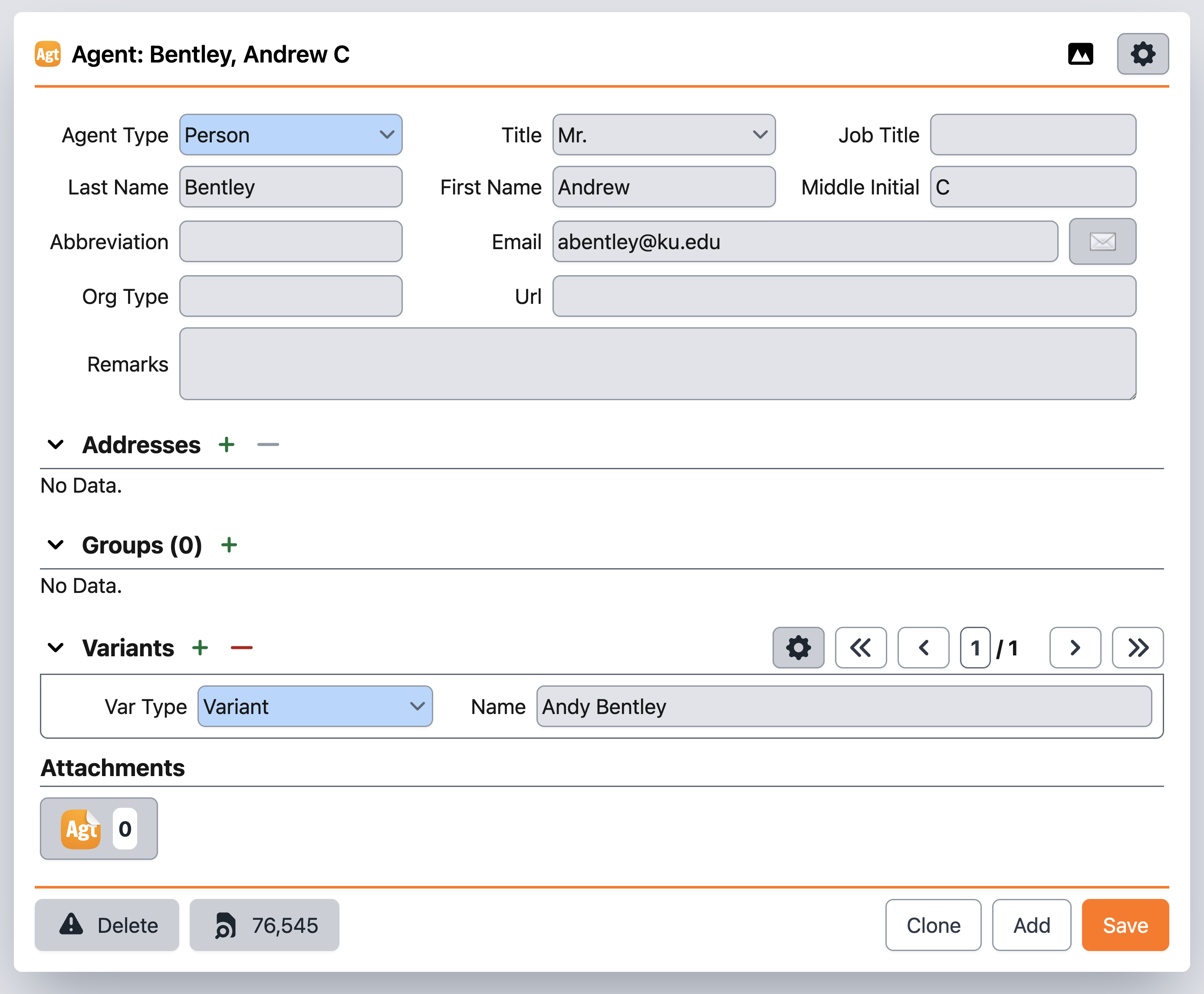
Hi Grant, all this has been very helpful! I’m in the process of implementing now, though, and I want to clarify something: At this moment, due to the fact that we are bastardizing something that is meant to be recording plant names, there is no option for creating other Agent Variant Types like “Maiden Name” or “AKA,” the only Type options are: 0 (Variant) or 1 (Vernacular Name). Am I correct, or am I missing something?
Hi @VHough,
Glad this could be of help! You can actually add additional options for variants!
If you go to Agent Variant in Schema Config for your instance (e.g. https://sp7demofish.specifycloud.org/specify/schema-config/en/AgentVariant/), you can edit the varType pick list:
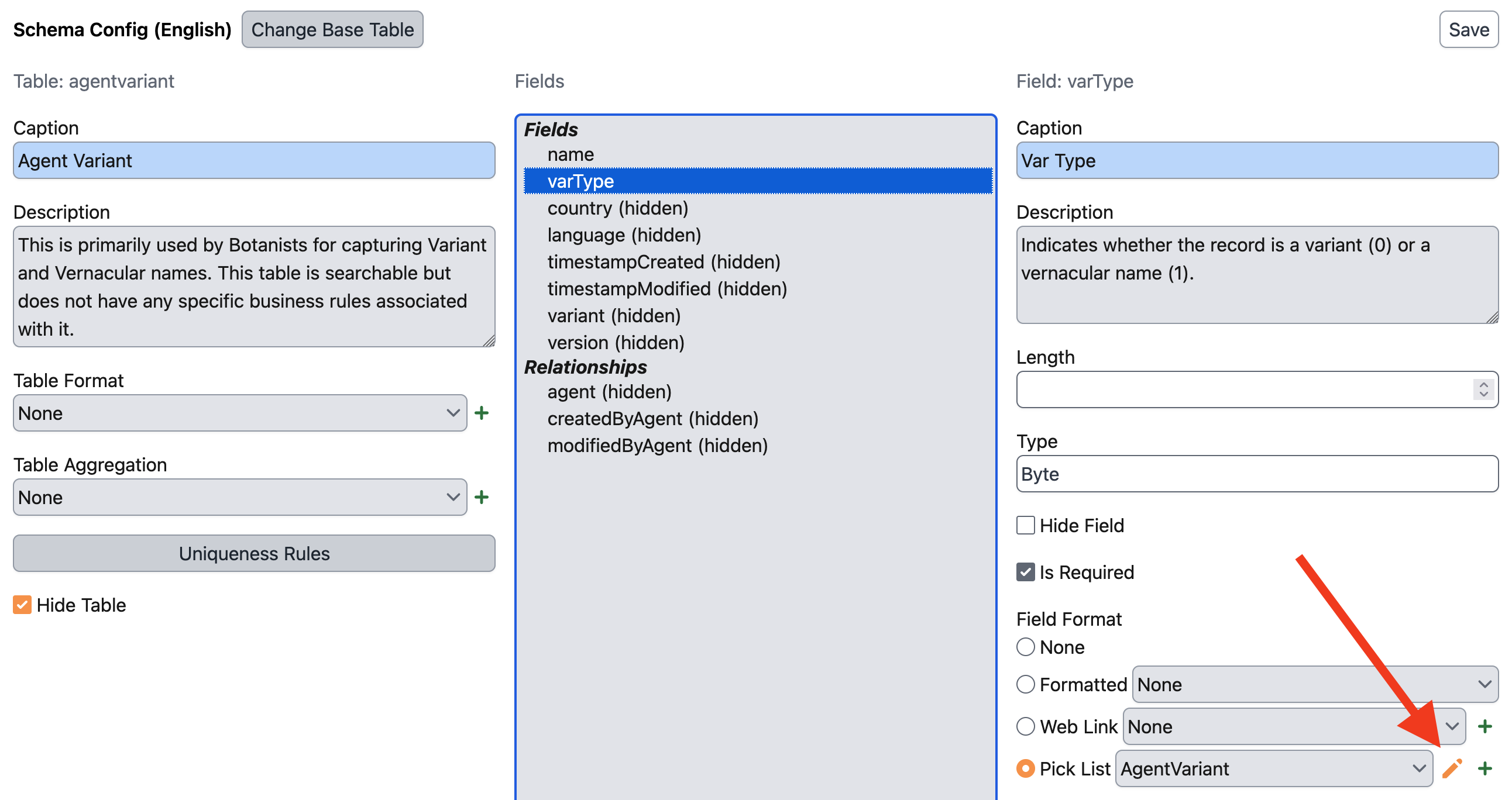
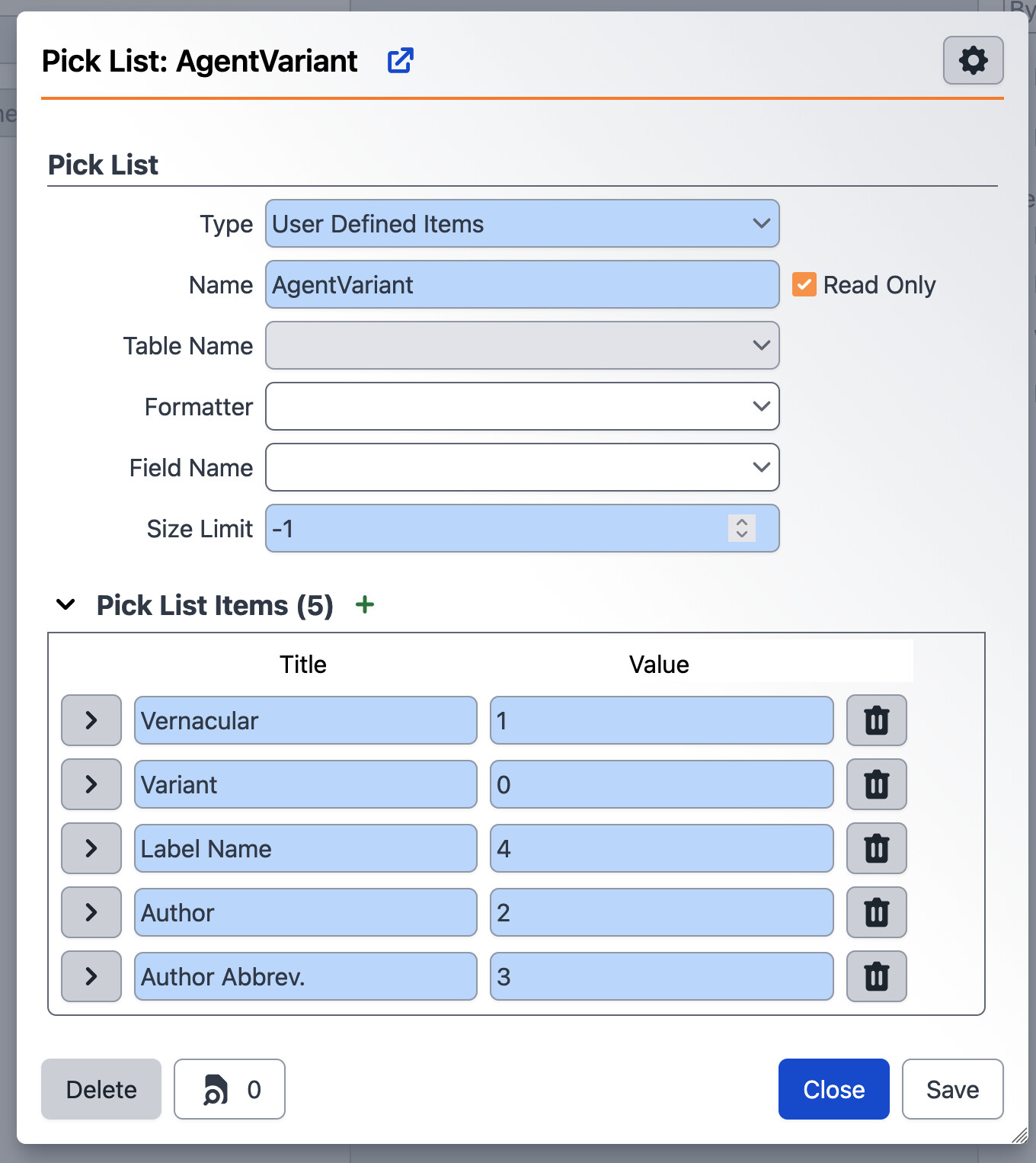
From here, you can add additional pick list items with a value that increments up from the highest current value:
@Grant I’ve always wondered – what does a “vernacular” name mean in the context of an agent?
@VHough In our database, I reduced that picklist down to only have two options: Variant and Misspelling, since it doesn’t matter to us what the source of a variant is, and we don’t link agents to ReferenceWork or Taxon. Mispellings are nevertheless important to flag because we want to make sure we never assert that something we know is incorrect is a viable alternative. I actually might add “Maiden name” as an option, I hadn’t thought of doing so before!
Hi @nfshoobs,
My understanding is that a “vernacular” name for an agent would just be any alternate or non-standard name for that person.
I realize that I’m a little late to this party: I’m now working to get my head around the Specify schema. We had a very functional database built on the original ASC model, but - for reasons that are too painful to relate - we’re now migrating to Specify.
I found it very important to be able to use alternative names for an agent (almost always a person). Hereʻs a real-world use case. If I wanted to get a list of all the papers on which John Doe was an author, or if John Doe was a collector, etc., I wanted to find them whether his name was recorded as Juan Doe, John Dough, etc. I considered it to be critically important to have the name for that author, collector, determiner, etc. recorded and retrievable exactly as it was used at the time. The most egregious example I recall was a Romanian entomologist who went by four very different names: one Romanian, one German, one Israeli, and … I don’t recall what the fourth was. In order to properly cite a publication it is critical to have the author’s name exactly as it was recorded on the publication. The same logic applies to maiden names or any other kind of name change.
We implemented that by having a table called Person_Synonyms with foreign keys pointing to the 2+ entries in the Person table. We could debate what the primary key for the synonyms table would best be, but my point is that the system retained (and linked) the separate entries in Person for the name variants. In doing so it would also preserve those primary keys.
My 2 cents.
Norm