While doing mass imports, we have just discovered something very odd with one particular collection (Vascular plants) that refuses to match the species names to existing ones in the tree. So as a result it creates multiple duplicate species that we would subsquently need to clean up again. It has no such issues with the genus or higher.
Thanks for sharing the spreadsheet! Could you also share the export mapping? We want to check if there are any additional fields mapped at a lower level (such as author, attribute, citation, etc.) that might lead Specify to treat them as unique.
Thank you for your patience while this Issue was being looked into!
I do believe I have found the cause of the duplicate Species records.
The Problem
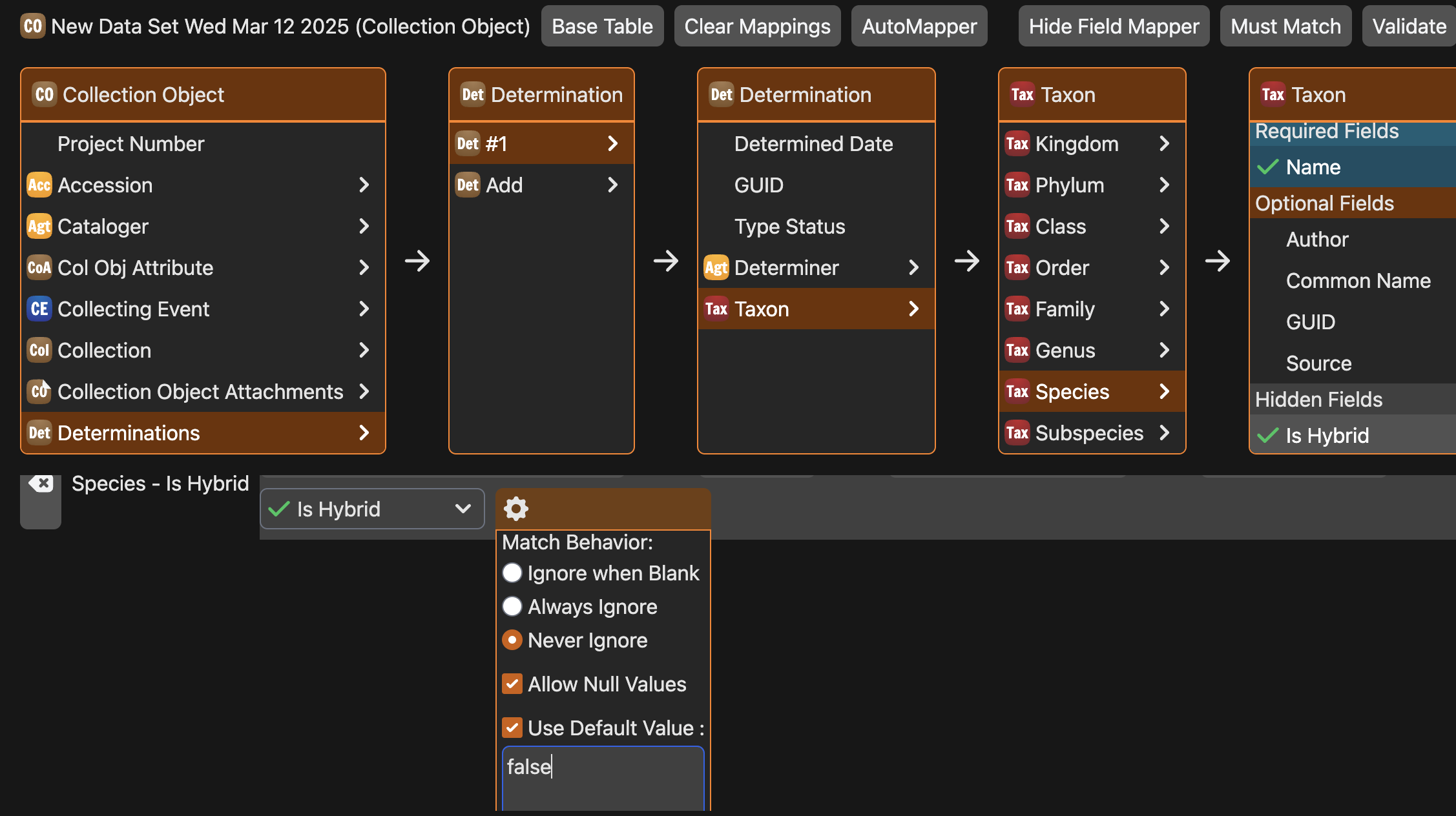
Ultimately, the problem lies in the seemingly innocuous mapping of Taxon -> Rank -> Is Hybrid and how Specify handles default field values when searching for existing Tree Records
Essentially, with isHybrid explicitly mapped with the default matching behavior, the searching and matching behavior for the associated record will always include the isHybrid field and value in the row. If the value of isHybrid for the row is blank (i.e., NULL), Specify will include a isHybrid=NULL in the search for existing records.
The problem with this is that isHybrid is marked as not nullable at a database level and is given a default value of False by the datamodel. In other words, if you don’t specify a isHybrid value for a Tree record, Specify will always default to isHybrid=False.
So for each Species in your Data Set, when Specify is trying to find a matching/existing Species, it is searching for isHybrid=NULL when there is no data in the cell: which will never result in a match and a new Species is created with a False isHybrid. Thus, each Species is being duplicated.
Below is a video which recreates and (mostly minimally) demonstrates the problem:
To track the problem, I have opened up a GitHub Issue which is slightly more technical and comprehensive in its explanation of the problem and proposes some proper solutions:
Feel free to provide any of your own feedback either here or on the GitHub Issue!
Solutions
Thankfully, there are some fairly easy workarounds until a proper solution is implemented.
You can do any of the following to resolve the problem: